Over the last few days since my previous post I’ve got thousands visitors, dozens of comments were posted and a few brave souls were even audacious enough to give it a try. Many of you provided valuable feedback and bug reports, so thank you all and keep the feedback coming!
I am now quite busy improving the software based on the feedback I’ve got so far and also on some bugs I found on my own, but before I have anything ready to be released, I thought I should post some kind of HOWTO that shows how to install and set it up, and shows a demo of the instance replacement process, also exposing the currently known issues you should expect when using it at this point.
It’s still not ready for production usage, but I’m working on it.
Installation
The initial set up is done using CloudFormation, so you will need to launch a new CloudFormation stack. Since the Stack creates a lambda function, due to a Lambda limitation you can only launch the stack in us-east-1 (Virginia), but the stack can handle resources in all the other regions available to normal AWS accounts. For multiple reasons, at the moment the Beijing and GovCloud regions are unsupported.
Using the AWS console
Follow the normal stack creation process shown in the screenshots below.
The template URL is all you need to set, it should be https://s3.amazonaws.com/cloudprowess/dv/template.json
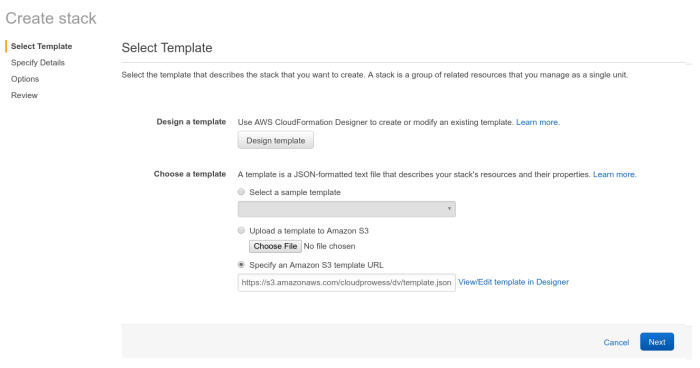
Give the stack a name, then you can safely go through the rest of the process. You don’t need to pass any other parameters, just make sure you confirm everything you set so far and acknowledge that the stack may create some IAM resources on your behalf.
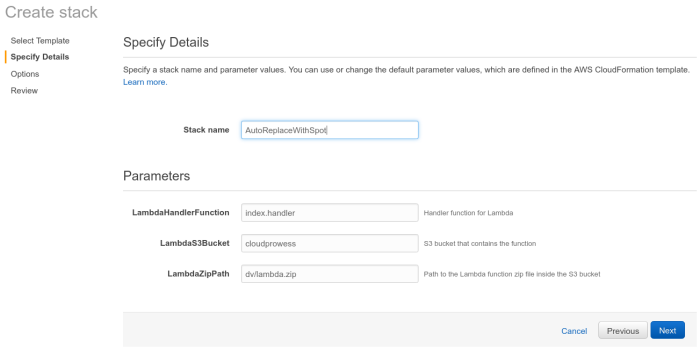
If everything goes well the stack will start creating resources.
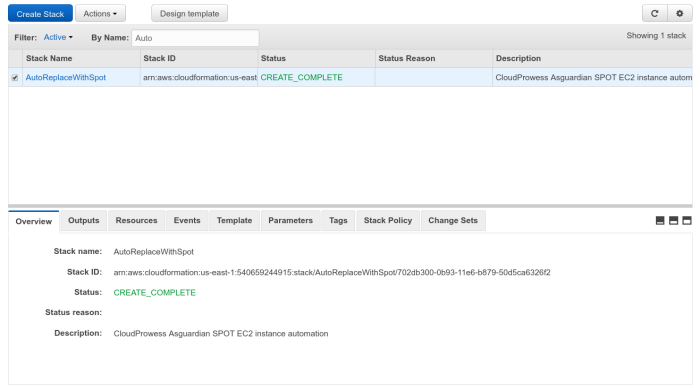
And after a few minutes you should be all set.
Using the AWS command line tools
If you already have installed the AWS command line tools, you can also launch the stack using the command line, using the following command:
aws cloudformation create-stack \ --stack-name AutoReplaceWithSpot \ --template-url https://s3.amazonaws.com/cloudprowess/dv/template.json \ --capabilities CAPABILITY_IAM
Configuration for an AutoScaling group
The installation using CloudFormation will create the required infrastructure, but your AutoScaling groups will not be touched unless you explicitly enable this functionality, which has to be done for each and every AutoScaling group which you would like to manage.
The managed AutoScaling groups can be in any other AWS region, the algorithm will run on all the regions in parallel, handling AutoScaling groups if and only if it was enabled for them. It makes no difference if your group is running EC2 Classic or VPC instances, since both are supposed to be supported. If you notice any issues when testing it in your setup, that’s likely a bug and would need to be reported.
Enabling it on an AutoScaling group is a matter of setting a tag on the group:
Key: spot-enabled Value: true
This can be configured with the AWS command-line tools using this command:
aws autoscaling create-or-update-tags \ --tags ResourceId=my-auto-scaling-group,ResourceType=auto-scaling-group,Key=spot-enabled,Value=true,PropagateAtLaunch=false
If you use the AWS console, follow the steps that you can see below:
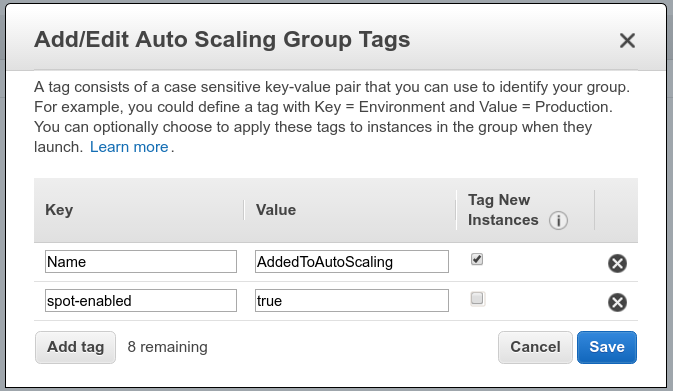
The tag isn’t required to be propagated to the new instances, so that checkbox can remain empty.
The AutoScaling group tags can also be set using CloudFormation, just insert this snippet into your AutoScaling group’s configuration:
"MyAutoScalingGroup": {
"Properties": {
"Tags":[
{
"Key": "spot-enabled",
"Value": "true",
"PropagateAtLaunch": false
}
]
}
}
Walkthrough
Going forward I’m going to show what happens after enabling it on an AutoScaling group.
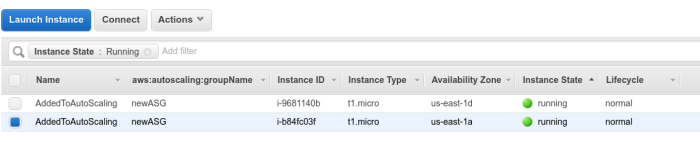
Once it was enabled on an AutoScaling group, the next run will launch a compatible EC2 Spot instance.
Note: the new spot instance is not yet added to any of your AutoScaling groups.
The new instance type is chosen based on multiple criteria, and as per the current algorithm(this is a known issue and it may be fixed at some point) it may not be the cheapest across all the availability zones, but it will definitely be cheaper and at least as powerful as your current on-demand instances.
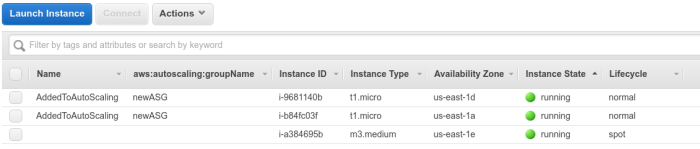
As you can see below, it launched a bigger m3.medium spot instance in order to replace a t1.micro on-demand instance. This also means that you can get bigger instances, such as c3.large spot instances, as long as their prices is the smallest of the instance types compatible with your base instance type.
The new instance’s launch configuration is copied with very small modifications from the one set on your on-demand instances, so the new instances will be as closely as possible configured to the instances previously launched by your AutoScaling group.
Note: We try to copy everything, including the user_data script, EC2 security groups(both VPC and Classic), IAM roles, instance tags, etc. If you notice any gaps, please report those as bugs.
After the spot instance is launched and running out of its grace period(whatever was set on the AutoScaling group), it will be added to the group, and an existing on-demand instance will be terminated.
The AutoScaling group also adds it automatically to any load balancer configured for the group, so the instance will soon start receiving traffic. In case of instances that start handling requests as soon as their user_data script finished executing, like for example if you are processing data from an SQS queue, that may have already happened a while back, so the instance may already be in use even before being added to the group.

Known bug: At the moment if the group is at its minimum capacity, the algorithm needs another run and temporarily increases the capacity in order to be able to replace an on-demand instance, and this should be more or less harmless assuming that the AutoScaling rules will eventually bring the capacity back to the previous level. Sometimes this can interfere badly with your scaling policies, in which case you may enter a spinning AutoScaling condition. It can be mitigated by tweaking the AutoScaling scaling down policy to make it less aggressive, like by setting a longer wait time after scaling down. This bug should be solved in the next release. This bug was fixed.
Continuing, in the next run, a second spot instance is launched outside the AutoScaling group:
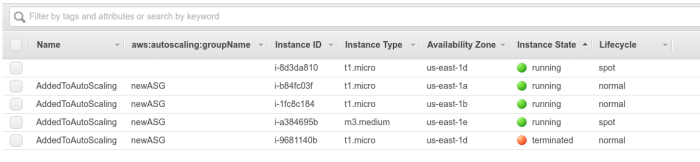
Then, after the grace period passed, it is added to the AutoScaling group, replacing another on-demand instance that is detached from the group and terminated:

This process repeats until you have no on-demand instances left running in the group, and you are only running spot instances.
If AutoScaling takes any scaling actions, like terminating any of the spot instances or launching new on-demand ones, we don’t interfere with it. But later we will attempt to replace any on-demand instances it might have launched in the meantime with spot equivalents, just like explained before.
Currently, due to the bug I mentioned previously, my setup ended up in a spinning state, but I managed to stabilize it by increasing the AutoScaling group’s scaling down cooldown period, and it eventually converged to this state: This bug was fixed.

Once I eventually release that bugfix, the group should converge to that state by itself, without any changes and much faster. This issue was fixed, the instances should be replaced smoothly.
Conclusions
Many people commented asking how does this solution compare with other spot automated bidders, such as the AWS-provided AutoScaling integration and the spot fleet API, as well as other custom/3rd party implementations.
I think the main differentiator is the ease of installation and use, which you can see in this post. There are a few rough edges that will need some attention, but I’m working on it.
Please feel free to give it a try and report any issues you may face.
Please see my initial post for announcements about software updates.

[…] Update: If you want to see this in detail and also to it in action, please also check out my next blog post. […]